This blog post introduces the “hidden methodology” behind many core works on deep music generation in Music X Lab. We hope it can help you better distill the main idea from technical details.
– Gus, Dec 2023
Background of automated music generation
For a long time, music generation has been modeled as a “sequence prediction” problem. As in estimating the stock price, the task of music generation is to predict a music sequence based on some contexts, say, to predict the melody given the underlying chords, or to predict the upcoming notes based on existing ones. However, we observed an intrinsic defect of such generation via prediction approach – in any given contexts, there are many ways/directions to develop the music, so which one shall the model follow?
Unfortunately, most data-driven approaches would not choose any particular direction, but somewhat an averaged version of all possibilities. This often leads to a mediocre music without a clear structure, and that is why most AI-made music still lacks the exploration and dynamic in genuinely creative works. Even worse, there is little room to interact with the black-box models except for sampling from the learned distribution repeatedly. From a musician’s perspective, composing a piece is certainly very different from predicting a stock’s price. What we need is not a “correct” estimate, but a creative choice. Moreover, we wish to interpret and control such choices as a way to extend our own musical expression.
A different philosophy – generation via analogy-making
A solution to the problems above lies in analogy-making — or, in a modern terms, music style transfer1. The underlying idea is that most creation is not entirely new but a recombination of existing features (representations). A simple example (in the visual domain) is a “red rabbit” – a rare thing in nature but almost everyone can create an image in their mind by applying “red” (a concept) to “rabbit” (another concept). Similarly, if a model can learn useful music concepts, we can generate new music by making an analogy, e.g., what if piece A was re-composed/re-arranged using a different feature (e.g. chord, texture, form, etc.).
Assuming we have M music features and N pieces, each piece with a unique value for each feature. Through analogy-making, we can in theory create (NM – N) new pieces by recombining the M features of the N pieces. That is a huge gain! From the lens of causality, such “generation via analogy-making” belongs to “counterfactual reasoning”, i.e., to imagine something non-existent based on observations.
Coming back to deep learning
The good news is that deep representation learning models are good feature learners, and we already see pioneer works in neural image style transfers. Now, it is our mission to work out solutions to: 1) learn abstract representations of music, 2) disentangle the representation into human-interpretable parts (concepts) using various inductive biases, and 3) control the generation by manipulating (sampling, interpolating, recombining, etc.) different music concepts.
Figure 1. The generation via analogy-making methodology: first do interpretable concepts learning via representation disentanglement, and then do controllable music generation.
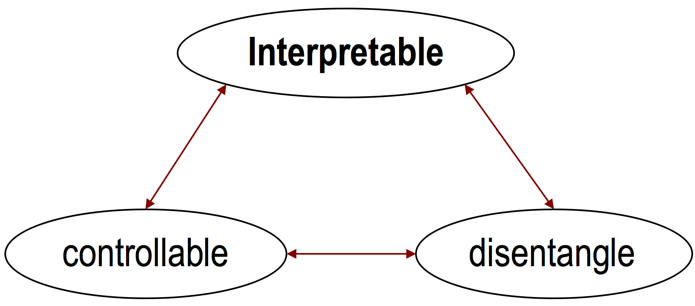
The graph above is referred to as the “trinity of interpretable representation learning” in Music X Lab. Many of our core works follow such methodology — disentangling “melody contour” and “rhythmic pattern” of monophonic melody using EC2VAE2, disentangling “chords” and “texture” of piano score using Poly-dis3, learning “piano texture” from both score and audio in A2S4, learning the “orchestration function” of multi-track polyphonic pieces in Q&A5, and disentangling “pitch” and “timbre” using a unified model for zero-shot source separation, transcription and synthesis6, etc. Several more recent works, e.g. whole-song generation7 and AccoMontage 38, even applied interpretable representations in a hierarchical setup.
On unifying sequence generation and representation disentanglement
An even better news is that “generation via prediction” and “generation via analogy-making” do not necessarily conflict; rather, we can unify these two methodologies — a straightforward approach we often use is to throw the learned disentangled representations into whatever generative model (autoregressive, diffusion, masked language model, etc.). In other words, let the learned disentangled representations be the “language” of the generative model. The underlying idea is that interpretable concepts shall be useful features for (downstream) generation tasks.
We can either just use these representations as “controls”, or even better, also ask the models to predict these disentangled representations. Such ”representation-enhanced generation” has two major benefits. First, the (entire) generation process becomes more interpretable and controllable. Second, the generation results are usually much more coherent, as the model is now producing music feature-by-feature, measure-by-measure, and sometimes even phrase-by-phrase rather than naive note-by-note or midi-event by midi-event.
Here are some examples of controllable generation using disentangled representation: 1) piano arrangement by predicting texture based on a lead sheet using polydis3, 2) a more flexible control of chord and texture using Polyfussion9, 3) flexible music inpainting using long-term (4 bar to 8 bar) melody and rhythm representations10 11, and 4) automatic orchestration generation based on “orchestration function representation” and chords using AccoMontage 38, and 5) whole-song generation7, a model that applies different feature controls on different levels of compositional hierarchy.
In the end, feature extraction and sequence modeling should go hand in hand. Concretely, we recently showed that predictive modeling can “return the favor” and help representation disentanglement — to use sequence prediction as an inductive bias for more interpretable disentanglement. The underlying idea is that a good representation should help us better predict the future. We will leave it as a rough idea in this blog, but you can check out SPS12 and also a line of research on self-supervised learning in the last suggested follow-up reading.
Suggested follow-up reading
- Symbolic Music Representation learning and disentanglement: from monophonic to polyphonic (coming soon)
- Multimodal Music representation learning:on connecting MIR with Music Generation (coming soon)
- Hierarchical disentanglement: towards effective and efficient sequence modeling (coming soon)
- What is proper inductive bias for self-supervised learning? (coming soon)
Reference
- G. Xia, S.Dai. “Music Style Transfer: A Position Paper,” 6th International Workshop on Musical Metacreation, Spain, June 2018. ↩︎
- R. Yang, D. Wang, Z. Wang, T. Chen, J. Jiang and G. Xia. “Deep Music Analogy Via Latent Representation Disentanglement,” in Proc. 20th International Society for Music Information Retrieval Conference, Delft, Nov 2019. ↩︎
- Z. Wang, D. Wang, Y. Zhang, G. Xia, “Learning Interpretable Representation for Controllable Polyphonic Music Generation,” in Proc. 21st International Society for Music Information Retrieval Conference, Montréal, Oct 2020. ↩︎
- Z. Wang, D. Xu, G. Xia, Y. Shan, “Audio-to-symbolic Arrangement via Cross-modal Music Representation Learning,” in Proc. 47th International Conference on Acoustics, Speech and Signal Processing, Singapore & Online, May 2022. ↩︎
- J. Zhao, G. Xia, Y. Wang. “Q&A: Query-Based Representation Learning for Multi-Track Symbolic Music re-Arrangement,” in Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence, Macao, August 2023. ↩︎
- L. Lin, Q. Kong, J. Jiang, G. Xia. “A unified model for zero-shot music source separation, transcription and synthesis,” in Proc. 22nd International Society for Music Information Retrieval Conference, Online, Nov 2021. ↩︎
- Under review. ↩︎
- J. Zhao, G. Xia, Y. Wang. “AccoMontage-3: Full-Band Accompaniment Arrangement via Sequential Style Transfer and Multi-Track Function Prior.” arXiv preprint arXiv:2310.16334, 2023. ↩︎
- L. Min, J. Jiang, G. Xia, J. Zhao. “Polyffusion: A Diffusion Model for Polyphonic Score Generation With Internal and External Controls,”in Proc. 24th International Society for Music Information Retrieval Conference, Italy, Nov 2023. ↩︎
- S. Wei, G. Xia, W. Gao, L. Lin, Y. Zhang, “Music Phrase Inpainting Using Long-term Representation and Contrastive Loss,” in Proc. 47th International Conference on Acoustics, Speech and Signal Processing, Singapore & Online, May 2022. ↩︎
- S. Wei, Z. Wang, W. Gao, G. Xia, “Controllable Music Inpainting With Mixed-level and Disentangled Representation,” in Proc. 48th International Conference on Acoustics, Speech and Signal Processing, Rhodes Island, Greece, June 2023. ↩︎
- X. Liu, D. Chin, Y. Huang, G. Xia, “Learning Interpretable Low-dimensional Representation via Physical Symmetry,” in Advances in Neural Information Processing Systems, New Orleans, US, Dec 2023. ↩︎